
Best API
Reduce OpenAI API cost without changing your workflow
Best API is a lower-cost, OpenAI-compatible API layer for developers.
It is designed for builders who want to reduce OpenAI API cost without changing their existing workflow.
Instead of switching platforms or rewriting your stack, you can keep using a familiar OpenAI-style request format while improving your unit economics.
Best API focuses on simplicity:
no complex routing, no heavy platform layers — just a straightforward way to lower cost with minimal migration.
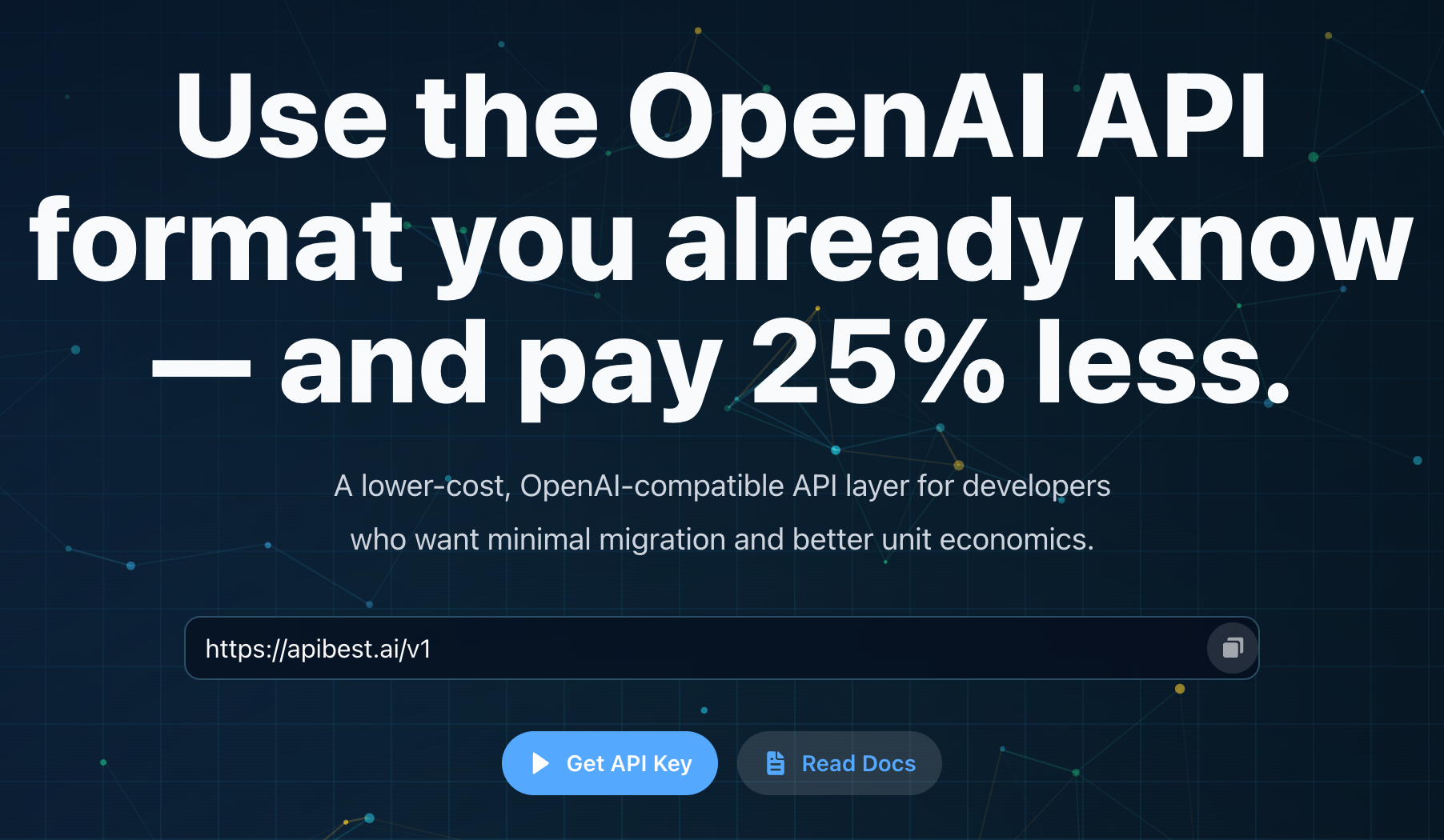
Features
- OpenAI-compatible request format and workflow
- Minimal migration (often just update base URL)
- Lower cost compared to standard OpenAI pricing
- Designed for developers and early-stage products
- Simple and focused — no unnecessary platform complexity
Use Cases
- Indie developers building AI-powered apps
- Early-stage startups optimizing API costs
- MVP products with growing token usage
- Content generation tools and chat-based apps
- Internal tools that rely on OpenAI-style APIs
Fazier Deal

Comments




The "just change the base URL" approach is really smart. Most cost-optimization tools require you to rethink your entire architecture, but keeping OpenAI compatibility means zero friction for teams already in production. Curious how latency compares to direct OpenAI calls — that's usually the tradeoff with proxy layers.

The "just update base URL" claim is compelling for production systems, especially for minimizing friction. Alexandra correctly brings up latency; any proxy layer inevitably introduces some overhead. I'd add questions around potential model versioning issues. For larger projects, the security implications of proxying all API traffic are also a critical consideration.

The "just update your base URL" positioning is smart because it removes the biggest friction in API switching — developers already have mental overhead from the product they're building, and asking them to refactor API calls on top of that kills adoption. The real test for something like this is model parity and reliability; if outputs diverge subtly from direct OpenAI calls, it creates debugging nightmares downstream. Would be useful to know how you handle model versioning — when OpenAI ships gpt-4o-mini updates, does Best API track those automatically or pin to a snapshot?

This is a clever solution to a real problem. OpenAI API costs add up fast, especially if you are running multiple agents or processing large volumes of text. The drop-in replacement approach is key — nobody wants to refactor their codebase just to save on inference costs. How does the quality compare on more complex reasoning tasks? That is usually where cost-optimized routing gets tricky.
Premium Products












Fazier Deal
Sponsors
BuyAwards
View all
Awards
View allMakers

Makers
Comments
The "just change the base URL" approach is really smart. Most cost-optimization tools require you to rethink your entire architecture, but keeping OpenAI compatibility means zero friction for teams already in production. Curious how latency compares to direct OpenAI calls — that's usually the tradeoff with proxy layers.
The "just update base URL" claim is compelling for production systems, especially for minimizing friction. Alexandra correctly brings up latency; any proxy layer inevitably introduces some overhead. I'd add questions around potential model versioning issues. For larger projects, the security implications of proxying all API traffic are also a critical consideration.
The "just update your base URL" positioning is smart because it removes the biggest friction in API switching — developers already have mental overhead from the product they're building, and asking them to refactor API calls on top of that kills adoption. The real test for something like this is model parity and reliability; if outputs diverge subtly from direct OpenAI calls, it creates debugging nightmares downstream. Would be useful to know how you handle model versioning — when OpenAI ships gpt-4o-mini updates, does Best API track those automatically or pin to a snapshot?
This is a clever solution to a real problem. OpenAI API costs add up fast, especially if you are running multiple agents or processing large volumes of text. The drop-in replacement approach is key — nobody wants to refactor their codebase just to save on inference costs. How does the quality compare on more complex reasoning tasks? That is usually where cost-optimized routing gets tricky.
Premium Products
New to Fazier?

Find your next favorite product or submit your own. Made by @FalakDigital.
Copyright ©2025. All Rights Reserved